
Systems ThatHealsThemselves


Reliability Engineering.
Practiced with Precision.
Observability, automation, and incident engineering - applied to systems that businesses stake their reputation on. This is the work that prevents headlines, not the work that makes them.
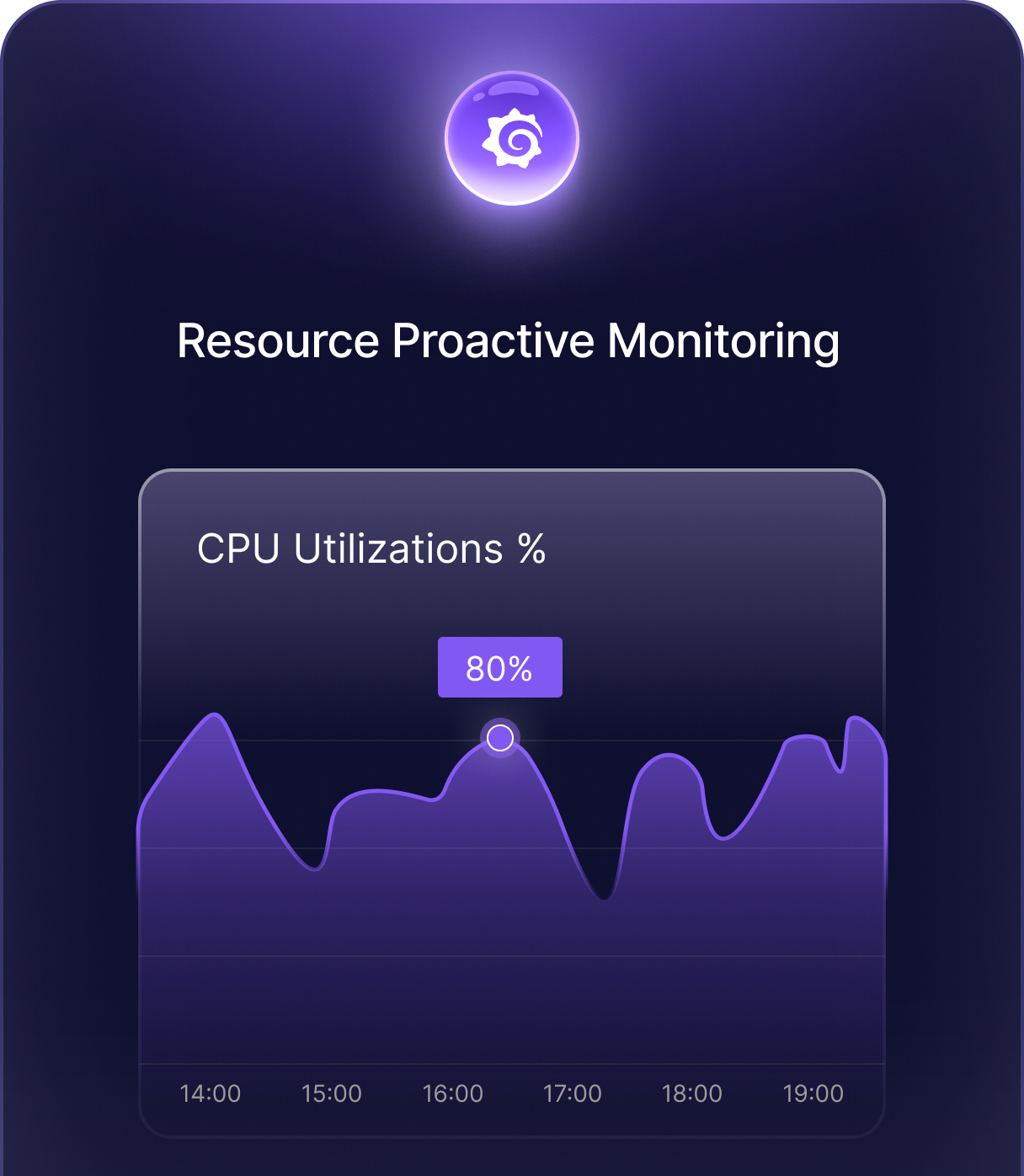
Reliability Engineered
by Design.
Four principles that govern how I approach every system, every incident, and every automation decision. Not methodology for its own sake - engineering with measurable outcomes.
Built on Tools That
Run Production.
Every tool in this stack has been used in live environments - not tutorials, not sandboxes. This is the ecosystem I operate in daily to keep infrastructure observable, automated, and resilient.

Where Is Your Infrastructure
Right Now?
Most teams don't have a reliability problem. They have a visibility problem. Here's how I diagnose where you are - and exactly what changes when I'm involved.
Validated by the Industry.
Not Just Claims.
Every certification here was earned through hands-on practice, not passive study. These represent the technical foundations I apply daily in production environments.

The Work Behind
The Metrics.
Two roles. One company. A clear trajectory - from building the observability foundation as an intern to owning reliability outcomes across production cloud environments as an engineer.
Work That Actually
Ships.
Real infrastructure problems, real solutions. Each project here has run in production and solved a problem that mattered.


Things You're Probably
Wondering.
The questions hiring managers and engineering leads ask most. Answered directly, without the interview performance.
I'm open to all working arrangements - remote, hybrid, or in-office. My focus is on contributing meaningfully to the team and the systems we're responsible for, wherever that work happens best.
Insights and
updates
Thoughts on reliability engineering, infrastructure automation, and building systems that last.
